This page describes a quick-start guide on the Python HWDB Upload Tool with a single example. We emphasize that the method described in this page is not the only way to employ the Tool. There are other ways with various helpful options that are described here.
With the example provided in this page, you will be able to:
- upload a component specification (thus, obtain its assigned DUNE PID)
- update a component specification (for a given PID)
- create and/or update a serial number of the component
- create and/or update the component’s location
- create links to its sub-components
- upload images to the component
- create and/or update the component’s tests
Getting ready
-
We strongly recommend to employ Anaconda (Python distribution), which should get you most of the needed packages for the Tool. It can be obtained from https://www.anaconda.com/download for free and is available for Windows, Linux, and macOS.
-
Next, obtain the zipped (or tar.gz, whichever you prefer) source code of the Tool from here. Make sure to grab the latest version, which is v1.2.3 at the time of this writing.
Installing the Tool:
-
Extract the downloaded source code to a directory of your choosing. For the purposes of this document, we will assume this directory is $HOME/DUNE-HWDB-Python.
-
To have the necessary paths available in your Bash shell, add the following lines to your .bashrc file. (If you are using a different shell, modify accordingly.)
export HWDB=~/DUNE-HWDB-Python export PATH=$HWDB:$HWDB/bin:$HWDB/devtools:$PATH export PYTHONPATH=$HWDB/lib:$PYTHONPATH
- Provide the executable permission to the followings:
chmod u+x $HWDB/hwdb-*
- If you don’t have reportlab on your devide, which doesn’t come with the Anaconda distro unfortunately,
the Tool will suggest you to install it. The Tool itself will run fine without this extra library, but it will not generate bar/QR-code labels in that case.
To install this, simple execute the following command:
pip install reportlab
Configuring the Tool:
-
Obtain your PKCS12 certificate through these steps. The obtained file name should be something like “usercred.p12”.
-
Before using the Tool, you must configure it to use your PKCS12 certificate.
hwdb-configure --cert <path-to-your-p12-file> --password <your password>
- Now try to execute the following command:
hwdb-configure
If everything is setup correctly, you should see a screen similar to the one below.
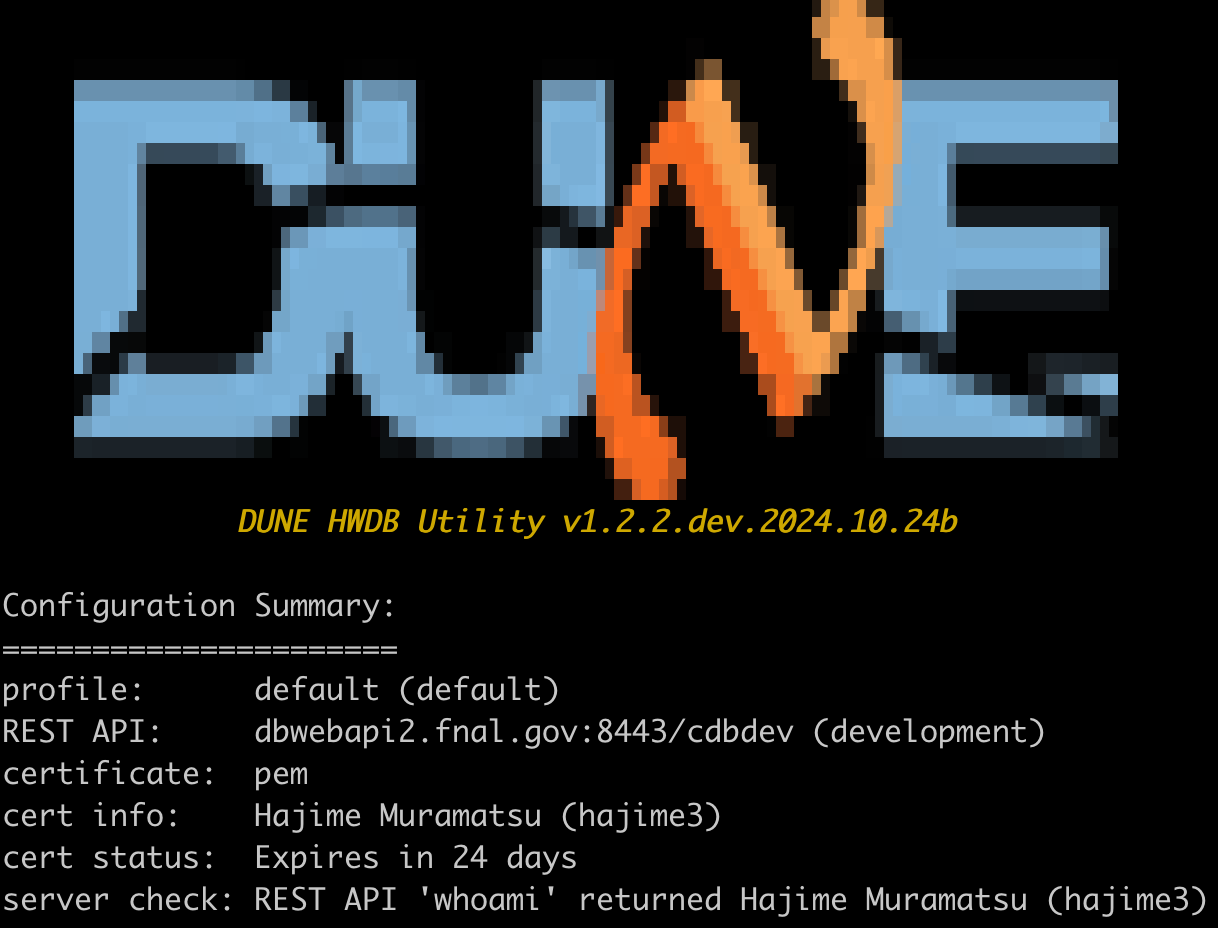 Notice that the REST API base path points to the development version of the HWDB, which is the default setup.
When you are ready to work with the official Production server, enter:
Notice that the REST API base path points to the development version of the HWDB, which is the default setup.
When you are ready to work with the official Production server, enter:
hwdb-configure --prod
Likewise, to set it back to Development, enter:
hwdb-configure --dev
Configuring a Component Type and a Test Type in the HWDB:
-
If your Component Type is already setup, skip this step.
-
We are going to use a Component Type ID, D00599800015, as an example in this page. This Component Type, thus, needs to be set up as described in the 03-Setting-up-Types.
-
In the Datasheet of this Component Specifications, insert the following (notice that you must have the Administrator privilege in order to modify Component Type definitions):
DATA: [] _meta: {}
- Similarly, create and define a Test Type (as described in the 03-Setting-up-Types.
In our example, we will use a Test Type name, My Test. Go ahead to define a Test Type with that name and again insert the followings to its Specifications:
DATA: [] _meta: {}
-
All contents uploaded by the Tool are stored within “DATA: []”.
-
“_meta: {}” is used by the Tool only and users should just ignore it.
Uploading contents to the HWDB
Understanding the basic concept:
-
In our example, a user provides the contents, that are uploaded to the HWDB, to the Tool by a spreadsheet file. The example spreadsheet file can be obtained from here: QuickStartExample.xlsx
-
The HWDB needs to know how the contents of the spreadsheet file should be structured/stored. A docket file does the job. Our example docket file can be obtained from here: QE-docket.json
-
In spreadsheet(s), user provides contents with specific column labels. There are specific label names that are reserved for the Tool. We list those special labels below. These special labels have specific meanings and we’ll go through them in the following subsections.
- External ID
- Serial Number
- Comments
- Manufacturer
- Manufacturer ID
- Manufacturer Name
- Institution
- Institution ID
- Institution Name
- Location
- Location ID
- Location Name
- Arrived
- Location Comments
- Image File
We’ll start to look at the example spreadsheet file first and understand our contents. We’ll then go through the docket file to see how it works, including setting up the database schema for Specifications.
QuickStartExample.xlsx: “My Items” sheet:
- Our example spreadsheet file includes 3 sheets. One of them, “My Items” sheet, looks like the below:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | Serial Number | Comments | Drawing Number | MySubComp 1 | MySubComp 2 |
| 2 | HA-MURAMATSU-00003 | here is my item | DFD-XX-FF00 | HA-MURAMATSU-00001 | HA-MURAMATSU-00002 |
| 3 | HA-MURAMATSU-00004 | another item | DFD-XX-FF01 | ||
| the first half of My Items sheet | |||||
| F | G | H | |
|---|---|---|---|
| 1 | Location | Arrived | Location Comments |
| 2 | (186) University of Minnesota Twin Cities | 10/14/2024 10:12:13 AM | comments for 1st item |
| 3 | (186) University of Minnesota Twin Cities | 10/13/2024 9:38:58 PM | comments for 2nd item |
| the second half of My Items sheet | |||
| Column | Description |
| A | It defines a specific Item, and thus acts as a PID. There is no specific scheme to define serial numbers, but each of them must be unique for a given Component Type. One could use External ID as its label name here, instead. In that case, you would have to specify existing PIDs. The Tool then overwrite the contents of the specified PIDs. |
| B | This column represents comments for each of the Items. |
| C | Drawing numbers, to be stored in each of the Item’s Specifications in the HWDB. |
| D & E | The label names here need to coincide with those functional position names that are defined in its Component Type definition. Notice that the Item, HA-MURAMATSU-00003, will have 2 sub-component links, one to HA-MURAMATSU-00001 and another to HA-MURAMATSU-00002, while the Item, HA-MURAMATSU-00004, will not have any sub-component link. |
| F | The column specifies a location of the Item. It expects both Institution ID and Institution name. If you like, you could only specify ID (name) with a label name, Institution ID (Institution Name), instead. |
| G | Represents arriving date&time of the corresponding Item. One can add a time-zone. Without it, by default it takes it in the North American Central Time Zone. |
| H | Represents comments for each locations. |
-
If you don’t have any sub-component to be linked, you could just remove the columns D & E altogether.
-
Similarly, if you don’t need to enter locations of your Items, go ahead to remove columns F, G, and H.
QuickStartExample.xlsx: “My Images” sheet:
- “My Images” sheet should look like the below:
| A | B | C | |
|---|---|---|---|
| 1 | Serial Number | Image File | Comments |
| 2 | HA-MURAMATSU-00003 | images/apple.jpeg | image 1 |
| 3 | HA-MURAMATSU-00003 | images/banana.jpeg | image 2 |
| 4 | HA-MURAMATSU-00004 | images/broccoli.jpeg | image 3 |
| 4 | HA-MURAMATSU-00004 | images/apple.jpeg | image 4 |
| My Images sheet | |||
| Column | Description |
| A | Represents the same Serial Numbers that are found in the My Items sheet. |
| B | Specifies the locations and file names of the images to be uploaded. |
| C | Comments for each image files. |
- Again, if you don’t have any image to be uploaded, you could delete the entire “My Images” sheet.
QuickStartExample.xlsx: “My Tests” sheet:
- “My Tests” sheet should look like the below:
| A | B | C | D | E | F | G | H | I | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Serial Number | Comments | Operator | Test Location | PSU Serial Number | Visual Inspection | PSU Manufacturer | PSU Test 1 | PSU Test 2 |
| 2 | HA-MURAMATSU-00003 | Looks good | Hajime | Minneapolis | 2PH30-230 | Passed | TOSHIBA | Failed | Passed |
| 3 | HA-MURAMATSU-00004 | Looks ok | Andy | Tucson | 2PH30-231 | Passed | TOSHIBA | Passed | Failed |
| the first half of My Tests sheet | |||||||||
| J | K | L | M | |
|---|---|---|---|---|
| 1 | Fan Serial Number | Fan Manufacturer | Fan Test 1 | Fan Test 2 |
| 2 | W0909101451 | Champion Lab | Passed | Failed |
| 3 | W0909101452 | Champion Lab | Failed | Passed |
| the second half of My Tests sheet | ||||
| Column | Description |
| A | Represents the same Serial Numbers that are found in the My Items and My Images sheets. |
| B | Comments on each of the Tests. |
| C-M | These columns represent my test data. We’ll describe how exactly we like to format them below. |
- Again, if you don’t need to upload any test data, but only Items, you could just delete this “My Tests” sheet.
QE-docket.json: “Values” blob:
- “Values” blob in QE-docket.json should look like the below:
"Values": { "Part Type ID": "D00599800015", "Institution": "(186) University of Minnesota Twin Cities", "Manufacturer": "(7) Hajime Inc" }
Here, you provide Component Type ID of the Items you like to upload (in this case, D00599800015), your Institution, and Manufacturer.
QE-docket.json: “Sources”:
- “Sources” in QE-docket.json should look like the below:
"Sources": [ { "Files": "QuickStartExample.xlsx", "Sheet Name": "My Items", "Encoder": "My Item Encoder" }, { "Files": "QuickStartExample.xlsx", "Sheet Name": "My Images", "Encoder": "My Image Encoder" }, { "Files": "QuickStartExample.xlsx", "Sheet Name": "My Tests", "Encoder": "My Test Encoder" } ]
-
Here you specify the 3 spreadsheet file names, the 3 sheet names, and the 3 Encoder names.
-
We have only one single spreadsheet file in our example. But we could have those 3 sheets in 3 different files separately.
-
We’ll describe each of the Encoders in the next sub-sections.
QE-docket.json: Encoders: “My Item Encoder”:
- “My Item Encoder” in QE-docket.json should look like the below:
"Encoder Name": "My Item Encoder", "Record Type": "Item", "Part Type ID": "D00599800015", "Schema": { "Specifications": { "DATA": { "type": "group", "key": "Serial Number", "members": { "Serial Number": "string", "Drawing Number": "string", "My Doc": { "value": "https://edms.cern.ch/document/2505353/" }, "Serial Number": "string", "Location": "string", "Arrived": "string", "Location Comments": "string" } } }, "Subcomponents": { "MySubComp 1": { "column": "MySubComp 1" }, "MySubComp 2": { "column": "MySubComp 2" } } }
-
Within the Specifications blob, its database scheme is defined.
-
“key” tells the Tool that “Serial Number” defines an Item (one-to-one correspondance between a “Serial Number” and an Item).
-
The “members” blob defines the scheme. In the database, we like to store them like the one shown below:
"Drawing Number": "DFD-XX-FF00", "My Doc" : "https ://edms.cern.ch/document/2505353/"
-
For “My Doc”, since we know the documentation link is the same for this Component Type, instead of specifying it in every row of “My Items” sheet, we provide the constant value here. Notice that we don’t need to specify the label name, “My Doc” in our sheet either.
-
The “Subcomponents” blob just specifies label names for sub-component PIDs (or Serial Numbers).
QE-docket.json: Encoders: “My Image Encoder”:
- “My Image Encoder” in QE-docket.json should look like the below:
"Encoder Name": "My Image Encoder", "Record Type": "Item Image", "Part Type ID": "D00599800015", "Schema": { "type": "group", "key": "Serial Number", "members": { "Serial Number": "string", "Image File": "string", "Comments": "string" } }
- Similar to “My Item Encoder” typesets of the labels are defined.
QE-docket.json: Encoders: “My Test Encoder”:
- “My Test Encoder” in QE-docket.json should look like the below:
"Encoder Name": "My Test Encoder", "Record Type": "Test", "Part Type ID": "D00599800015", "Test Name": "My Test", "Schema": { "Test Results": { "DATA": { "type": "group", "key": "Serial Number", "members": { "Serial Number": "string", "Operator": "string", "Location": "string", "PSU": { "type": "group", "key": "PSU Serial Number", "members": { "PSU Serial Number": "string", "Visual Inspection": "string", "PSU Manufacturer": "string", "PSU Test 1": "string", "PSU Test 2": "string" } }, "Fans": { "type": "group", "key": "Fan Serial Number", "members": { "Fan Serial Number": "string", "Fan Manufacturer": "string", "Fan Test 1": "string", "Fan Test 2": "string" } } } } } }
-
Again, it has a very similar form to what we have seen in Item and Image Encoders.
-
This time, however, it has a nested structure in its scheme. E.g., this scheme would store the contents in “My Tests” sheet as shown below:
"Serial Number": "HA-MURAMATSU-00003", "Operator" : "Hajime", "Location" : "Minneapolis", "PSU" : [ "PSU Serial Number": "2PH30-230", "Visual Inspection": "Passed", "PSU Manufacturer" : "TOSHIBA", "PSU Test 1" : "Failed", "PSU Test 2" : "Passed" ], "Fans" : [ "Fan Serial Number": "W0909101451", "Fan Manufacturer" : "Champion Lab", "Fan Test 1" : "Passed", "Fan Test 2" : "Failed" ]
Let’s upload them:
- If you have modified your sheet(s) and docket file according to your needs, you should be ready to upload them. Execute the following command. Don’t worry. It will not upload, yet. It will only check the contents of the provided files.
hwdb-upload QE-docket.json
- If you don’t see any error message from the above command-line, let’s upload them for real:
hwdb-upload QE-docket.json --submit
- If everything goes well, you should see a screen similar to the one shown below:
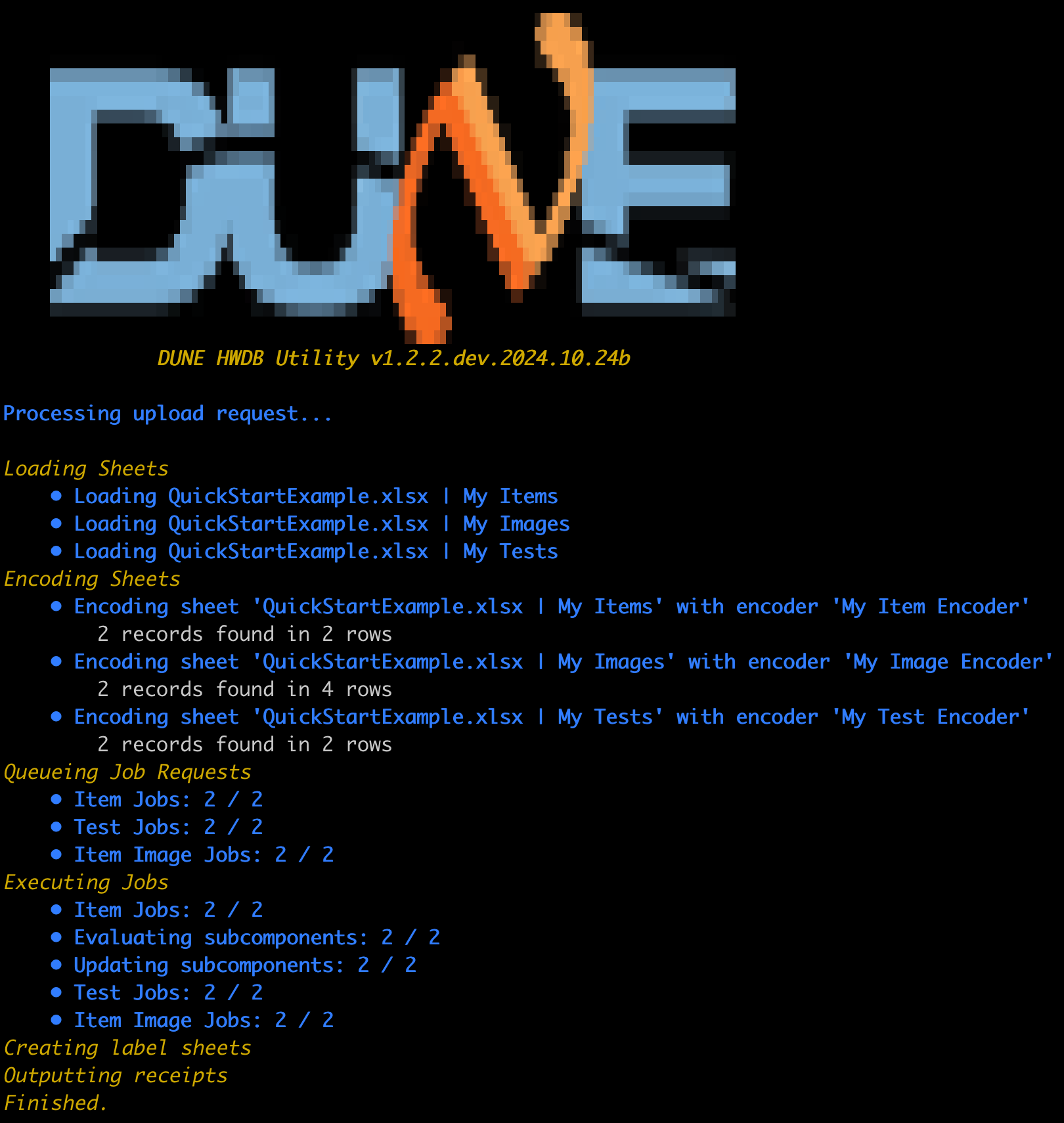 and new PIDs are assigned to each of the newly uploaded Items (i.e., the corresponding Serial Numbers).
and new PIDs are assigned to each of the newly uploaded Items (i.e., the corresponding Serial Numbers).
-
Again, if you don’t need to upload Tests, you can remove the Test sheet from the spreadsheet file and the Tests portion from “Sources” and “Endoder” of the docket file.
-
Likewise, if you don’t plan to upload images, remove the corresponding parts from the spreadsheet and docket files.
with External IDs (or Serial Numbers) that already exist in the HWDB
- If you upload with Serial Numbers (or External IDs) that already exist in the HWDB, it will overwrite the existing Item Specifications and Tests (don’t worry, their histories are kept in the HWDB). This is actually a useful feature when you need to update contents in the HWDB.
After uploading contents to the HWDB
-
Once you are done with uploading, there should be a new directory (folder) created locally with a directory name of timestamp.
- Go into that directory. There should be two files:
- Items-D00599800015.xlsx (the provided Component Type ID is used for its file name)
- ItemLabels.pdf
- Items-D00599800015.xlsx was generated by the Tool, based on what you just uploaded, and thus, based on what the HWDB current has.
- It contains information of the uploaded Items. No info on uploaded images/Tests, yet.
- Thus, it contains the DUNE PIDs that were assigned by the HWDB, along with the corresponding Serial Numbers.
-
ItemLabels.pdf contains labels of bar- and QR-codes of the uploaded Items (there should be only two Items uploaded in our example).
- Every time you upload, the Tool creates this directory locally. It also creates a softlink, “latest”, that points to the directory created most recently.
Bar/QR-code labels
-
The generated ItemLabels.pdf has actually 27 pages (in our example).
-
It contains not only both QR-codes and bar-codes, but with various sizes of labels. Currently it produces the paper/label sizes that are shown below:
-
With requests, we can easily add other paper/label sizes. Or update the Tool so that users can provide these sizes at run time.
-
Below we show two of the generated 27 pages as an example: 67×72 mm label size of QR-code and 51.5×26.6 mm size of bar-code, on A4 papers.
